

KeyBERT: Keyword Extraction using BERT (Decoding NLP Libraries) #Shorts
Education
Introduction
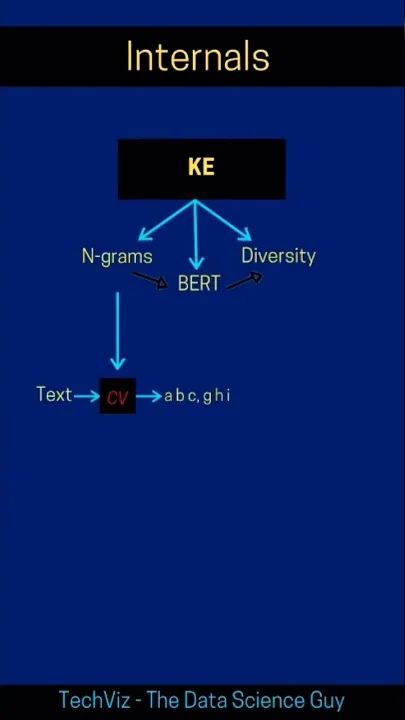
In this article, we will delve into the popular keyword extraction library called KeyBERT. KeyBERT is a user-friendly keyword extraction tool that leverages the power of BERT to identify key phrases that best represent a document. The process involves three main steps: first, extracting n-grams; then determining relevancy; and finally, ensuring diversity in the extracted keywords.
The method begins by utilizing a count vectorizer to generate a list of potential n-grams, which are then fed into the BERT model alongside the document to convert them into a high-dimensional space. By calculating the distances between these representations, KeyBERT ranks the n-grams based on their relevance to the document. The diversity module then comes into play to reduce redundancy in the extraction process, offering options such as maximum margin relevance or maximum diversity.
Authors suggest maximizing the similarity of keywords to the document while minimizing their similarity to other candidate keywords. By following these guidelines, KeyBERT ensures the extraction of the most representative and distinct keywords for any given text.
Introduction
Keyword extraction, KeyBERT, BERT, NLP libraries, keyword ranking, document representation, diversity module, relevance, similarity
Introduction
What is KeyBERT? KeyBERT is a keyword extraction library that utilizes BERT to identify key phrases that best represent a document.
How does KeyBERT work? KeyBERT operates in three sequential steps: extracting n-grams, determining relevancy, and ensuring diversity in the extracted keywords.
What is the role of the diversity module in KeyBERT? The diversity module in KeyBERT helps reduce redundancy in the keyword extraction process by offering options such as maximum margin relevance or maximum diversity.
What guidelines can authors follow when using KeyBERT for keyword extraction? Authors are advised to maximize the similarity of keywords to the document while minimizing their similarity to other candidate keywords to ensure the extraction of representative and distinct keywords.